作者:李哲龙链接:https://www.zhihu.com/question/53851014/answer/158794752来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先说下为什么要并行,众所周知目前的深度学习领域就是海量的数据加上大量的数学运算,所以计算量相当的大,训练一个模型跑上十天半个月啥的是常事。那此时分布式的意义就出现了,既然一张GPU卡跑得太慢就来两张,一台机器跑得太慢就用多台机器,于是我们先来说说数据并行,放张网上copy的图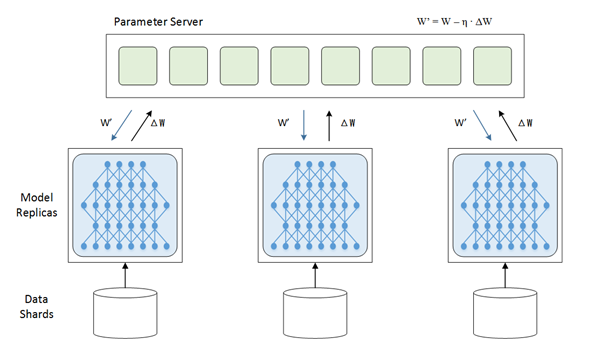 在上面的这张图里,每一个节点(或者叫进程)都有一份模型,然后各个节点取不同的数据,通常是一个batch_size,然后各自完成前向和后向的计算得到梯度,这些进行训练的进程我们成为worker,除了worker,还有参数服务器,简称ps server,这些worker会把各自计算得到的梯度送到ps server,然后由ps server来进行update操作,然后把update后的模型再传回各个节点。因为在这种并行模式中,被划分的是数据,所以这种并行方式叫数据并行。然后呢咱们来说说模型并行,深度学习的计算其实主要是矩阵运算,而在计算时这些矩阵都是保存在内存里的,如果是用GPU卡计算的话就是放在显存里,可是有的时候矩阵会非常大,比如在CNN中如果num_classes达到千万级别,那一个FC层用到的矩阵就可能会大到显存塞不下。这个时候就不得不把这样的超大矩阵给拆了分别放到不同的卡上去做计算,从网络的角度来说就是把网络结构拆了,其实从计算的过程来说就是把矩阵做了分块处理。这里再放一张网上盗的图表示下模型并行:
在上面的这张图里,每一个节点(或者叫进程)都有一份模型,然后各个节点取不同的数据,通常是一个batch_size,然后各自完成前向和后向的计算得到梯度,这些进行训练的进程我们成为worker,除了worker,还有参数服务器,简称ps server,这些worker会把各自计算得到的梯度送到ps server,然后由ps server来进行update操作,然后把update后的模型再传回各个节点。因为在这种并行模式中,被划分的是数据,所以这种并行方式叫数据并行。然后呢咱们来说说模型并行,深度学习的计算其实主要是矩阵运算,而在计算时这些矩阵都是保存在内存里的,如果是用GPU卡计算的话就是放在显存里,可是有的时候矩阵会非常大,比如在CNN中如果num_classes达到千万级别,那一个FC层用到的矩阵就可能会大到显存塞不下。这个时候就不得不把这样的超大矩阵给拆了分别放到不同的卡上去做计算,从网络的角度来说就是把网络结构拆了,其实从计算的过程来说就是把矩阵做了分块处理。这里再放一张网上盗的图表示下模型并行:
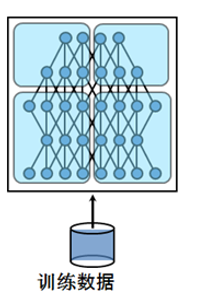
最后说说两者之间的联系,有的时候呢数据并行和模型并行会被同时用上。比如深度的卷积神经网络中卷积层计算量大,但所需参数系数 W 少,而FC层计算量小,所需参数系数 W 多。因此对于卷积层适合使用数据并行,对于全连接层适合使用模型并行。 就像这样: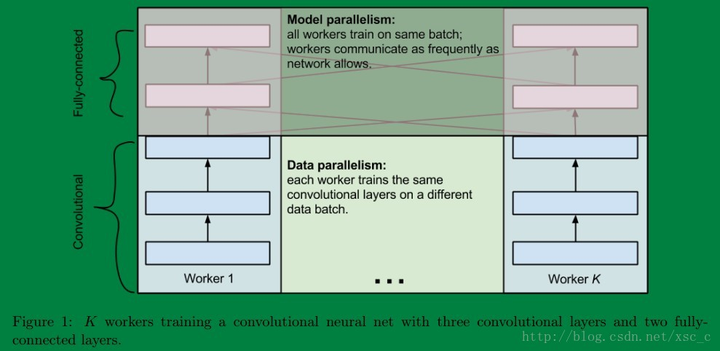 关于这个更多地可以参考这篇博客,说的挺详细的卷积神经网络的并行化模型–One weird trick for parallelizing convolutional neural networks
关于这个更多地可以参考这篇博客,说的挺详细的卷积神经网络的并行化模型–One weird trick for parallelizing convolutional neural networks